Reproducible-Research-Things
Reproducible Research Checklist
Step 1 - Documentation
Document all the procedures for your experiment, trial, survey, or study so that researchers unfamiliar with your project can understand your workings. Record where results and working data will be saved and save that information where your chief investigator, supervisor or team members can access it. Use a word document or text file to record the steps.
This training provides some tips on how to start documenting and more.
Step 2 Naming conventions
From the outset, name your files consistently and logically to protect yourself from misplaced or lost data and possible project delays. Establishing a consistent file naming convention from the start will ensure files are easier to find, process, understand, and version control. A good, basic convention includes standard order, date formats, vocabulary, numbers and punctuation, e.g.
YYYY-MM-DD_ProjectAbbreviation_FileInformation_Version.filetype
Two examples of filenames using this system:
2020-01-20_BehChange_Survey1_RawData.xls
2020-01-20_BehChange_Survey1_WorkData_V1.xls
Step 3 Folder Structure
Create a standard folder structure to keep files organised. This is very helpful when sharing files with colleagues. Folders, like files, should follow a logical naming convention. One tip is to create folders prefixed by number to reflect your workflow steps. Adding a leading zero for numbers 1-9 will ensure folders appear in the right sequence. Create and store a README.txt file that explains the contents of the different folders.
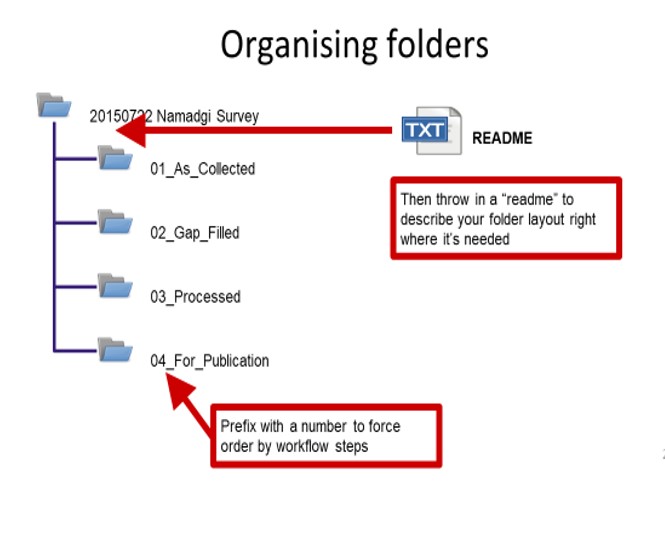
Read more about the use of folders.
Step 4 Automation
Automate repetitive tasks to eliminate monotony, potential errors, and claw back time that could be better spent on research. Options include using an MS Excel text function, formula or macro, learning to create reusable scripts to repeat data cleaning tasks in OpenRefine, using pipes and loops in the Unix shell, and using task scheduler for Windows or Automator for MacOS. Check out this online advanced Excel training or the beginners’ book on data analysis with Excel.
Step 5 Version Control
A version control system allows you and others to keep track of changes in your data, your files or your process. Keep master files of all raw data intact by using separate copies of the data for processing. Document the versions of analysis software you use for data processing. If you are using random numbers in your research, save your random seed generator number as part of your working data. Use workflow programs and save the workflow as part of your documentation. If you are writing scripts, use Git to keep track of versions. This way, you can later reproduce your results. Read more about version control.
Step 6 Cloud Backups
Keep a copy of all your data (working, raw and completed) in cloud-based storage. This ensures that if you suffer a computer failure, lose your laptop, accidently delete or overwrite your data, or your data becomes corrupted, your research is most likely retrievable. Griffith offers three different types of cloud storage designed especially for research. Find the storage you need.
Step 7 Computer Security
Securing your computer and network means that you are at far less risk of a data breach or hack. Establish good strong passwords and encrypt your computer’s hard drive. Use a password manager such as LastPass to make the use of unique, strong passwords easy. Found out how to do these here.
Step 8 Separating Identified Variables
When protecting privacy of participants, locations or other sensitive information, plan de-identification early as part of your data management planning. Retain original unedited versions of data for use within the research team and for preservation. Create a de-identification log of all replacements, aggregations or removals made. Store the log separately from the de-identified data files. Identify replacements in text in a meaningful way, e.g., in transcribed interviews indicate replaced text with [brackets] or use XML markup tags. Read more.
Step 9 Permanent Identifiers for your Published Results
Once you have completed your project, make your research data discoverable, accessible and possibly re-useable through the use of a persistent identifier such as a Digital Object Identifier (DOI). A DOI is a unique identifier which can be assigned to publications, data sets and associated outputs such as grey literature, preprints, workflows, algorithms, software, and more. DOIs are used for citation, linking with other research, indexing and metrics. Find out how.
This checklist is based on 9 Reproducible Research Things, a workshop created jointly by Griffith University’s eResearch Services and the Griffith University Library.
Return to home page

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.