1 - Data quality

Scenario - Are your datasets future-proof? Can your provide your data and methods?
“Tidy data” principles
As your research progresses, new possibilities for enquiry might be revealed, and you may want to use a new method to analyse your data. Depending on how you recorded and stored your data, it may take a lot of time-consuming work to reconfigure your datasets before you can process the new analysis. While all the necessary data may exist within your datasets, there may be no simple and reliable method for extracting it.
The principles of tidy data developed by Hadley Wickham offer a way of recording your data, be it in spreadsheets or database tables, so that every element within those datasets can easily be accessed for new analysis and modelling. Even if a dataset needs to be reconfigured before being imported into the new software, it will be a simple process to produce the necessary file.
The fundamental principles of tidy data are:
- Each variable is a column
- Each row is an observation
- Each cell contains one value.
By arranging all the variables of an observation along a single row, all elements about that observation are contained within a clearly delineated record: the single row. With all variables recorded in columns, these observations of a patient, a survey respondent, an historical event, a biological sample etc, are reliably linked to their subject.
Tidy data provides both the stability and the flexibility to reliably process and export data to any system; including running processes and modelling which later become desirable or significant for your research.
In a spreadsheet, this format must not vary; neither to accommodate additional data for an individual observation, nor to create an aesthetically pleasing layout e.g. merged cells.

With the requirement for each cell to contain a value, it is important for each cell to contain only one. This will isolate and label the information about a variable, and simplify the process of accessing it when required. As an example, when recording the addresses of respondents, the use of a single cell or line for the entire address makes potentially useable data difficult to access. By dividing these details across several columns, the potential exists to model additional data based on location.
Read Hadley Wickham’s article on Tidy data. Using a spreadsheet could you apply some of these principles to your data from the beginning of a project or during a project?
To take datasets from outside sources or from inexact processes such as webscraping and prepare them for analysis along with your tidy data, you may need to:
- convert the format or structure of the data
- remove duplicate or irrelevant observations
- standardise the format of observations
- change naming conventions
- correct errors
- or preform many more adjustments to make a dataset suitable for your processes.
The terms “data cleaning” and “data wrangling” are often used interchangably but they can be defined separately as:
- Data wrangling: transforming and mapping a dataset
- Data cleaning: removing or correcting data
While small datasets could be altered manually, large scale datasets will require specialised functions or software to process multiple values.
Learn to apply some tidy data methods with this online module using the open source data cleaning software OpenRefine.
Everyday more and more data is generated and collected, much of which is suitable for some form of analysis. Depending on the nature of your research, you might have data from multiple sources as separate data tables. When you are working with multiple data tables, this is known as having relational data.
This is because the data sets have relations between certain variables in a pair of tables, not just the individual datasets. It is important to note that although you may have any number of data tables, the relations are a defined between the pairs first and foremost.
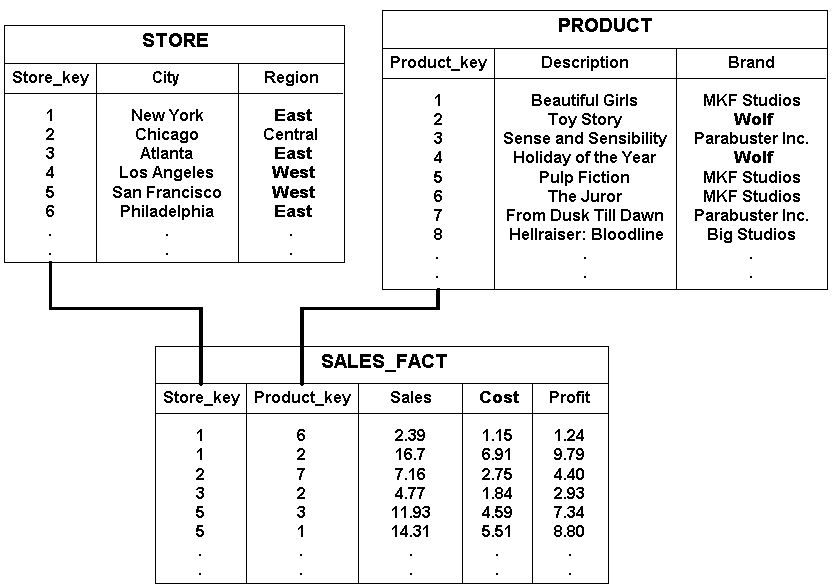
Data quality, espcially within the context of relational databases can take on a set of diverse definitions. An often cited framework is total data management quality (TDQM) theory. (Wang & Strong, 1996)
TDQM theory is defined below:
| Data quality category | Data quality dimensions |
|---|---|
| Intrinsic data qualtiy | Believability, Accuracy, Objectivity, Reputation |
| Contextual data quality | Value-Added, Relevancy, Timeliness, Completeness, Appropriate amount of data |
| Representational data quality | Interpretability, Ease of understanding, Representation consistently, Concise representation |
| Accessibility data quality | Accessibility, Access Security |
Further reading on the TDQM theory is available at:
Wang, R. (1998). Quality Ma A Product Perspective on Total Data. COMMUNICATIONS OF THE ACM, [online] 41(2). Available at: http://web.mit.edu/tdqm/www/tdqmpub/WangCACMFeb98.pdf.
- Learn R for Data Science, specifically the tidyr package, or Python for Data Science and the pandas package.
- Attend an Introductory coding course held at your institution such as Griffith’s Coding Workshops.
- If you are really new to coding we recommend completing a number of the short interactive, online lessons from 100 Days of Code - The Complete Python Course by Replit pior to attending an R or Python software carpentry workshop.