5 - Naming Conventions

What is a File Name?
File names are names that you create when saving a new file, and which are listed in the directory of a folder.
What is a File Naming Convention?
A File Naming Convention (FNC) is a system for naming your all your files, where the filename includes a description of the contents and the context. This is a system that is best established as early as possible; ideally before collection research data. The FNC is then used each time a new file is created for your research.
Three principles for file names:
There are three key principles to guide file naming convention development, as defined by Data Carpentry and Martinez (2015):
- Machine readable
- Human readable
- Plays well with default ordering
Lets discuss each key principle below.
Machine readable
Within the context of file naming conventions, being machine readable means:
- Spaces have been avoided. Ideally there are no spaces in any file names.
- Special characters are used in lieu of spaces i.e. _ or -
- Case sensitivity is consistent
Another concept in machine readbilty is globbing.
Globbing is the concept of using a wild card symbol, typically a * followed by an extension or consistent string. This wildcard tells the computer to search for all files with that extension or string. For example * .jpg will search for all JPEG files in a directory. An example is shown below:
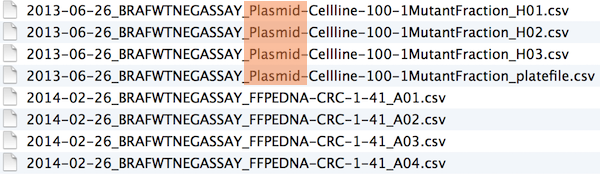
Human readable
Ensuring your file naming convention is human readable will depend on the context, background knowledge of research user(s), and character spaces availability. In short, use descriptive words. There will be examples of this further below.
Plays well with default ordering
Default ordering is best achieved with numbers. This can be chronological i.e. date, or logical i.e. 01, 02, 03…
Depending on the research and your teams preference, a common word could prefix the numeric ordering system. For example:
- lake01_depth.r
- lake02_depth.r
- lake03_depth.r
- so on….
Benefits
If implemented early and consistently, a standardised system or convention for naming files can:
- make file naming easier
- facilitate access, retrieval and storage of files
- make it faster to navigate files
- guard against misplacing or losing files
- assist with version control
- identify obsolete or duplicate records
- avoid backlogs or project delays by presenting a clear and real-time display of the current or completed work.
Former PhD student and subsequent founder of the Figshare platform, Mark Hahnel, highlights a common challenge:
‘During my PhD I was never good at managing my research data. I had so many different file names for my data that I always struggled to find the correct file quickly and easily when it was requested. My former Principle Invesitgator was so horrified upon seeing the state of my data organisation that she held an emergency lab book meeting with the rest of my group when l was leaving’.
Research Information, April/May 2014
Develop a plan for your team on how to name files
Your research team should agree on the following elements of a file name prior to data collection:
- Vocabulary - choose a standard vocabulary for file names, so that everyone uses a common language
- Punctuation - decide when to use punctuation symbols, capitals and hyphens
- Dates - agree on a logical use of dates so that they display chronologically i.e. YYYY-MM-DD
- Order - confirm which element should go first, so that files on the same theme are listed together and can therefore be found easily
- Numbers - specify the amount of digits that will be used in numbering so that files are listed numerically e.g. 01, 002, etc.
Consider the following recommendations:
- Capitalise the first letter of every new word with no intervening spaces
- i.e.
PAHospitalAdmissionICU_2010_2020_Raw.csv
- i.e.
- Keep filenames a reasonable length and keep file name information (metadata) separated using upper and lower case
- i.e.
Image02_PacificOcean_20200621.jpg
- i.e.
- Use logical order for sequential number with padded zeros
- i.e. instead of
1,2,3use001, 002, 003 or 01, 02, 03
- i.e. instead of
- For Version numbers consider
V1, V2and multiple versionsV1, V2, V2.1etc. - Document your FNC in a
ReadMe.txtor other documentation file in main shared project folder. It can be useful for staff orientation.
See this example below which uses:
-
standard date formatfollowed byfile topic informationseparated byunderscores _, with words usingCapitalCaseand ending in thefile type. -
Naming convention:
Date_Location_Sensor.filetype -
Format example:
YYYYMMDD_SiteA_SensorB.CSV -
Applied example:
20220621_MtGravatt_Humidity.CSV
Some characters may have special meaning to software or the operating system of the computer. Avoid using the following when you are naming files:
/ \ " ' * ; - ? [ ] ( ) ~ ! $ { } > # @ & | spaces tabs newlines
Source: IBM Knowledge Centre
- Create an easy naming convention for your data files and documents, using the guidance above.
- Dates are best stored with YYYYMMDD as files can be re-ordered chronologically.
- Document your file naming convention in a Readme.txt file and save it with your files.
For more file naming options, read and follow Edinburgh University’s simple 13 Rules for file naming conventions.
Do you have a policy in your team around naming conventions? If not, this is a great way of discussing the priorities of the research data.
The Minnesota Historical Society (2015) has published a very comprehensive policy development checklist for file naming conventions. Each aspect of developing a holistic file naming convention is detailed below, although only some may be relevant to your research use cases:
Persistence: File names should not require human explanation once the creator(s) of the convention have moved on to other work. With robust stakeholder input, and dedicated time, a framework should be developed that lasts the test of time .
Access and ease of use: Policy should favour simplicity and logic, particularly for new users of the policy. Through simplification, records will be consistently named and ultimately easier to access and organise when needed.
Ease of administration: If your research requires a degree of legislative oversight, then your FNC policy should empower this. Specifically, the FNC policy will leverage university computing infrastructure where possible to manage records, gather metadata or assist auditing.
Scalability: If it is likely that you will have hundreds or thousands of files requiring naming, then make sure you account for this. Particularly if using numeric prefixes to satisfy the above principle of playing well with default ordering. That is, if you only use two numeric placeholders (000,001,002 etc.) then you can only have 999 files. This could become problematic if you ever find yourself with 1000+ files.
Define the metadata: Metadata forms the first layer of identification when referencing a file name. It is also the first layer in protecting sensitive and non-sensitive files. For example, by prefixing your files with sensitive and releasable respecitively, you can prevent sensitive files from being accidentally transferred out of storage, which may breach other policy or legislative requirements.
Universal retrieval: If you work in a large team, ensuring files can be access reliably and efficiently is key to streaminling the research process. To address this point, you may need to consider what file storage system you are using and any security layers protecting sensitive data.
Define file naming boundaries: If a large number of researchers are likely to have a role in file naming, ensure that there is adequate training and/or guidance set out in policy. During such training or when giving guidance, be sure to define the boundaries for what is acceptable and unacceptable when naming files. This will support policy compliance that then supports your ongoing operational/legal requirements.
Source: Electronic Records Management Guidelines (2015) ELECTRONIC RECORDS MANAGEMENT GUIDELINES. Minnesota Historical Society. Available at: https://www.mnhs.org/preserve/records/electronicrecords/erfnaming.php (Accessed: January 24, 2023).
Internal Resources
- Talk to your Research Support Services librarian at library@griffith.edu.au.